
|
32893| 385
|
[科技] 韬(τ)定律?万物皆可叠? |
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
|
| |
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
Archiver|手机版|小黑屋|上海互联网违法和不良信息举报中心|网上有害信息举报专区|962110 反电信诈骗|举报电话 021-62035905|Stage1st
( 沪ICP备13020230号-1|![]() 沪公网安备 31010702007642号 )
沪公网安备 31010702007642号 )
GMT+8, 2026-5-27 04:49 , Processed in 0.215601 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5
© 2001-2026 Discuz! Team.


 发表于 2026-5-25 09:53
发表于 2026-5-25 09:53





 DUV仙人,这个名字好
DUV仙人,这个名字好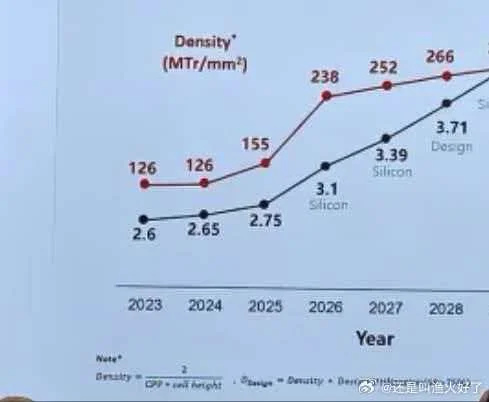



 NB
NB


